レプリカ交換モンテカルロ法による探索¶
ここでは、レプリカ交換モンテカルロ法によって、回折データから原子座標を解析する方法について説明します。 具体的な計算手順はNelder-Mead法による最適化と同様です。
サンプルファイルの場所¶
サンプルファイルは sample/single_beam/exchange にあります。
フォルダには以下のファイルが格納されています。
bulk.txtbulk.exeの入力ファイルexperiment.txt,template.txtメインプログラムでの計算を進めるための参照ファイル
ref.txt計算が正しく実行されたか確認するためのファイル(本チュートリアルを行うことで得られる
best_result.txtの回答)。input.tomlメインプログラムの入力ファイル
prepare.sh,do.sh本チュートリアルを一括計算するために準備されたスクリプト
以下、これらのファイルについて説明したあと、実際の計算結果を紹介します。
参照ファイルの説明¶
template.txt, experiment.txt については、Nelder-Mead法による最適化と同じものを使用します。
入力ファイルの説明¶
ここでは、メインプログラム用の入力ファイル input.toml について説明します。
input.toml の詳細については入力ファイルに記載されています。
以下は、サンプルファイルにある input.toml の内容です。
[base]
dimension = 2
output_dir = "output"
[algorithm]
name = "exchange"
label_list = ["z1", "z2"]
seed = 12345
[algorithm.param]
min_list = [3.0, 3.0]
max_list = [6.0, 6.0]
step_list = [1.0, 1.0]
[algorithm.exchange]
numsteps = 1000
numsteps_exchange = 20
Tmin = 0.005
Tmax = 0.05
Tlogspace = true
[solver]
name = "sim-trhepd-rheed"
run_scheme = "subprocess"
[solver.config]
cal_number = [1]
[solver.param]
string_list = ["value_01", "value_02" ]
degree_max = 7.0
[solver.reference]
path = "experiment.txt"
exp_list = [1]
[solver.post]
normalization = "TOTAL"
ここではこの入力ファイルを簡単に説明します。 詳細は入力ファイルのレファレンスを参照してください。
[base] セクションはメインプログラム全体のパラメータです。
dimension は最適化したい変数の個数で、今の場合は2つの変数の最適化を行うので、2 を指定します。
output_dir は出力先のディレクトリ名です。省略した場合はプログラムを実行したディレクトリになります。
[algorithm] セクションは用いる探索アルゴリズムを設定します。
交換モンテカルロ法を用いる場合には、 name に "exchange" を指定します。
label_list は、value_0x (x=1,2) を出力する際につけるラベル名のリストです。
seed は擬似乱数生成器に与える種です。
[algorithm.param] サブセクションは、最適化したいパラメータの範囲などを指定します。
min_list は最小値、 max_list は最大値を示します。 step_list はモンテカルロ更新の際の変化幅(ガウス分布の偏差)です。
[algorithm.exchange] サブセクションは、交換モンテカルロ法のハイパーパラメータを指定します。
numstepはモンテカルロ更新の回数です。numsteps_exchangeで指定した回数のモンテカルロ更新の後に、温度交換を試みます。Tmin,Tmaxはそれぞれ温度の下限・上限です。Tlogspaceがtrueの場合、温度を対数空間で等分割します
[solver] セクションではメインプログラムの内部で使用するソルバーを指定します。
Nelder-Mead法による最適化のチュートリアルを参照してください。
計算実行¶
最初にサンプルファイルが置いてあるフォルダへ移動します(以下、本ソフトウェアをダウンロードしたディレクトリ直下にいることを仮定します).
$ cd sample/single_beam/exchange
順問題の時と同様に、 bulk.exe と surf.exe をコピーします。
$ cp ../../sim-trhepd-rheed/src/bulk.exe .
$ cp ../../sim-trhepd-rheed/src/surf.exe .
最初に bulk.exe を実行し、 bulkP.b を作成します。
$ ./bulk.exe
そのあとに、メインプログラムを実行します(計算時間は通常のPCで数秒程度で終わります)。
$ mpiexec -np 4 odatse-STR input.toml | tee log.txt
ここではプロセス数4のMPI並列を用いた計算を行っています。
(Open MPI を用いる場合で、使えるコア数よりも要求プロセス数の方が多い時には、
mpiexec コマンドに --oversubscribe オプションを追加してください。)
実行すると、 output ディレクトリ内に各ランクのフォルダが作成され、
各モンテカルロステップで評価したパラメータおよび目的関数の値を記した trial.txt ファイルと、
実際に採択されたパラメータを記した result.txt ファイルが作成されます。
ともに書式は同じで、最初の2列がステップ数とプロセス内のwalker 番号、次が温度、3列目が目的関数の値、4列目以降がパラメータです。
# step walker T fx x1 x2
0 0 0.004999999999999999 0.07830821484593968 3.682008067401509 3.9502750191292586
1 0 0.004999999999999999 0.07830821484593968 3.682008067401509 3.9502750191292586
2 0 0.004999999999999999 0.07830821484593968 3.682008067401509 3.9502750191292586
3 0 0.004999999999999999 0.06273922648753057 4.330900869594549 4.311333132184154
また、各作業フォルダの下にサブフォルダ LogXXXX_00000000 (XXXX がグリッドのid)が作成され、ロッキングカーブの情報などが記録されます。
(各プロセスにおけるモンテカルロステップ数がidとして割り振られます。)
各ランクフォルダにある result.txt には、各レプリカでサンプリングされたデータが記録されていますが、これを温度ごとのサンプルに整列しなおしたデータが output/result_T*.txt として出力されます。 * は温度のインデックスを表します。
最後に、 output/best_result.txt に、目的関数 (R-factor) が最小となったパラメータとそれを得たランク、モンテカルロステップの情報が書き込まれます。
nprocs = 4
rank = 1
step = 282
walker = 0
fx = 0.008414800224430936
z1 = 5.164773671165013
z2 = 4.226467514644945
なお、一括計算するスクリプトとして do.sh を用意しています。
do.sh では best_result.txt と ref.txt の差分も比較しています。
以下、説明は割愛しますが、その中身を掲載します。
#!/bin/sh
sh prepare.sh
./bulk.exe
time mpiexec --oversubscribe -np 4 odatse-STR input.toml
echo diff output/best_result.txt ref.txt
res=0
diff output/best_result.txt ref.txt || res=$?
if [ $res -eq 0 ]; then
echo TEST PASS
true
else
echo TEST FAILED: best_result.txt and ref.txt differ
false
fi
計算結果の可視化¶
output/result_T*.txt を図示することで、 R-factor の小さいパラメータがどこにあるかを推定することができます。
以下のコマンドを実行すると、 output/result_T1.txt のサンプル点をプロットした 2次元パラメータ空間の図 result.png が作成されます。
$ python3 plot_result_2d.py
作成された図を見ると、(5.25, 4.25) と (4.25, 5.25) 付近にサンプルが集中していることと、
R-factor の値が小さいことがわかります。
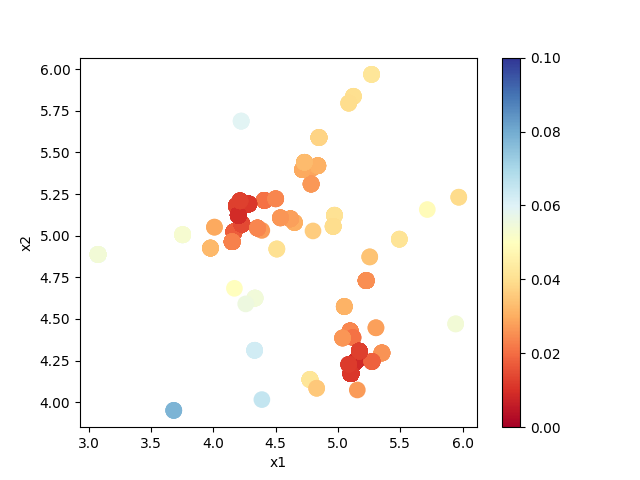
サンプルされたパラメータと R-factor 。横軸は value_01, 縦軸は value_02 を表す。¶
また、 [solver] セクションの generate_rocking_curve パラメータを true にすると、 RockingCurve_calculated.txt が各サブフォルダに格納されます。
これを用いることで、Nelder-Mead法による最適化での手順に従い、実験値との比較も行うことが可能です。